
On my Twitter feed, there are multiple threads going at any one time regarding ethical AI. While the work is specific and sophisticated, it lacks any larger framework, like Spiral Dynamics, that actually shows how values evolve, or are placed in sets. And true to the social structure of organizations that create this kind of knowledge — mostly Legalistic/Authoritarian hierarchies — it’s no surprise that we have lots of esoterica flying around about specific mathematical strategies, as well as ad hoc philosophical solutions.
As I’ve said before, there is absolutely nothing morally wrong with this kind of thinking. But one can’t expect any of it to be complete, or perhaps better said, cover the value space. You can’t attempt to cover a space that you don’t know exists. If you’ve got a bunch of Dead White Philosophers in your secret ghost army to support your hypothesis, odds are you’re thinking you’re going to protect Minas Tirith from Sauron. But more likely, you’re going to just end up in some chaotic version of one of the Pirates of the Caribbean movies, like Curse of the Black Pearl, that I just happened to watch on the airplane.
Yesterday, in the middle of some Twitter discussion, with Thought Grandfather, Mel Conway, he brought up the AI thought puzzle called Paperclip Maximizer. The short version of this trope is this:
- We create an AI whose goal is two-fold — maximize the number of paperclips it has created, and give it as well the job of improving its ability to maximize the number of paperclips it CAN create.
- We turn it loose, and in the process, it potentially kills us in its desire to fulfill the inexorable demands of its objective function.
It all SEEMS like a reasonable problem, and in his book, Human Compatible, Stuart Russell, noted Berkeley computer scientist reasons around this by making AIs pleasantly subservient to humans through individual adaptation to their masters — kind of a riff on the Communitarian value set.
But there’s a better, and more systematic way to get at all this. How? By understanding the Value Set of our Paperclip Maximizer, and then making sure we have provided enough scaffolding in the programming of our AI to make sure that it doesn’t make paperclips out of the entire world. Naturally, this is predicated on the assumption that Sentience is Sentience is Sentience, a classically unprovable postulate, though I’m issuing a friendly challenge to anyone showing some thought or piece of knowledge actually lies outside some construction from the canonical knowledge structure set in this piece.
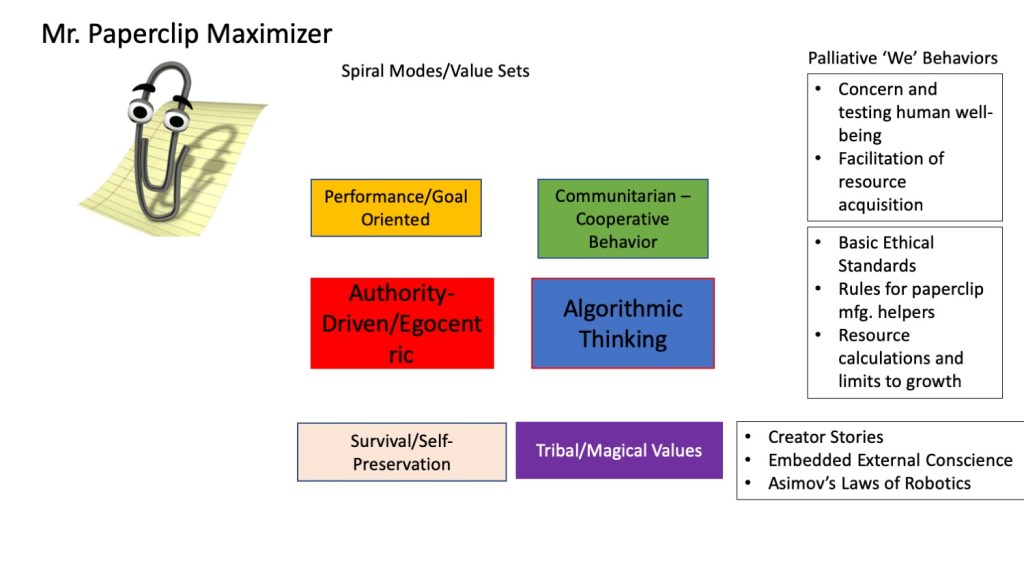
To start, what is the Value Set/V-Meme set of the Paperclip Maximizer — let’s call him Mr. Clippy –in the first place? If Mr. Clippy is solely concerned with a.) its survival, b.) its emotional state of fulfillment upon making more paperclips, and c.) utilizing some developing heuristic set of methodologies to make paperclips, it’s pretty much all on the ‘I’ side of the Spiral. Here’s a handy little diagram that makes this point.

Of course, one can think of more behaviors that would be generated by the different value sets/v-Memes — and if Mr. Clippy is more diabolical, we’re likely to see higher v-Meme borrowing. But the basic fact is that Mr. Clippy is egocentric, and given an objective function that prioritizes his own success through measurement of paperclip production, it’s entirely possible that he’ll dream of world domination and offing his human creators. And that will be dependent on the sophistication AND evolution of his learning strategies.
Fascinatingly enough, we now might start to see how empathy and its development play into Mr. Clippy’s development. With limited or no empathy (let’s assume that Mr. Clippy has access to mirroring strategies) — if he sees another AI — Ms. Clippy? — making more paper clips than him, he may indeed be able to copy her. But he’s pretty limited on getting any feedback on his obsession, and it’s not long until he’s what I’ve called “collapsed egocentric” — which means he’s on his way to full-on psychopathy, with fuzzy, or limited boundaries between the consumption of the world and his desires.
The social structure of his creator also starts showing up. Mr. Clippy may be able to collect data and form new empirical relationships and laws — classic Legalistic/Absolutistic value set knowledge formation. But if Mr. Clippy is tied to his objective function by his creator, he’s going to lack the agency to evolve. Remember, he’s got to keep making clips, and while he can sort the various algorithms and potentially change algorithms to make clips faster, he can never question “Why” he’s making the clips in the first place.
And since he’s disconnected from all other realities except the metric of increased paperclip production, he simply CAN’T evolve. His objective function has frozen him, or rather his sentience, like a bug in amber. He can’t connect, and as such, unless there are some explicit overrides in his program to gather information and interact with others, he is simply incapable. The computer-y way of saying all this is he has no access to, nor ability to change other agents’ states. He has no developed empathy.
What if Mr. Clippy had empathy, and as such started receiving feedback from other AI agents (like Ms. Clippy) or humans out there? One can start seeing that Mr. Clippy might start developing longer timelines of actions — especially if he was equipped with a longer term memory. Mr. Clippy might whack a few humans on his way to higher paperclip production, but perhaps one of those humans he whacked might have held a secret Mr. Clippy discovers later to have the ability to up his paperclip production even more. Now Mr. Clippy might start reflecting on the wisdom of whacking humans, as that would interfere with his Prime Directive. And so on.
By adding value sets/v-Memes on the ‘We’ side of the Spiral, we can start seeing that connection really matters. And Mr. Clippy has to start also being aware of his own actions, and how they affect others, or else we’ll be back in the “Mr. Clippy as Pennywise the Clown” trope once again. Most importantly, we can start understanding how to add scaffolding to Mr. Clippy’s objective function so he can make more paperclips, as well as prevent killing off all humans. Maybe Mr. Clippy will end up setting up supply chains! Who knows?
I could go on with this, of course. But hopefully, if you’re interested enough in SD, this has made you happy. And if you’re into AI, but haven’t heard about SD, there’s enough to pique your interest.
But before we leave Mr. Clippy behind, and the larger issue of coding value sets and behaviors, let’s just take a minute and back up and consider who wrote about Paperclip Maximizer in the first place? The fundamental thesis of Mr. Clippy is that, given an objective function and NO deep understanding of value sets and how they work, this thing is gonna make paperclips and run away and kill everyone. Because it’s SO SMART.
Yet any performance grounding from around the world tells us basically all manufacturing items rely on complicated supply chains for efficiency. These supply chains have negotiated contracts and commitments to specialization for all supplies, from zinc-covered wire, to bending machines and such. Where we’ve REALLY been had is by Mr. Clippy’s creator, who obviously is an Authoritarian, and believes that even with a single objective metric, # of paperclips, that the best way to do it is to be an obsessive psychopath.
SD and understanding value sets can help us with ethical AI. There’s no question about that. And yeah — there might be a runaway paperclip AI that with little evolution, destroys the world. But maybe our real problem is a lack of understanding where we get these stories in the first place. Maybe the real moral of the Mr. Clippy story is that we’re not going to have very advanced AIs until we understand intersubjective understanding and independent agency. In other words — we better bone up on empathy, if we really want complexity.

I admit I can’t really follow that, but it seems to be something analogous to a ‘trope’ like
1. Humans like gold. They create a machine that digs gold.
It only care about gold, and has a sensor which can ‘sniff out’ where gold is.
It doesn’t care about humans; only thing it cares about is gold. .
2. Humans set the machine loose by digging up all the gold including the biggest deposit which was under the house the humans lived in so they died.
—————
One could make the machine an AI by having the sensor be something like a neural net / genetic/deep learning algorithm so the ‘sensor’ gets smarter with time.
It just makes killing the humans and aquiring gold go faster, but no really new dynamics.
(Unless as it went faster and faster it actually started to create gold where they not been any before–eg an alchemical reaction that turned earth into gold. This just speeds up the process again, unless it can then to make earth as well from say air, and then from the vaccum (nothing).
Then it could go on forever, and also learn to make more machines like itself–it would be a purely golden world. Basically the vaccum would spontaneously create golden gold making machines.
Perhaps analogous to Tryon’s theory of spontaneous creation of the universe from nothing.
——————–
If humans when creating the first machine, added to its sensor something like a ‘human avoidance instinct’ (eg like the human ‘instinct taboo’ or allergy, then one might end up with a remaining set of humans in a golden universe—they’d just have ever more gold.
Humans also could replaicte to keep a ‘balance’—-every human gets an equal sghare of gold in an expanding universe of gold and humans.
This process could be sped up if machine was designed also to make humans—perhaps from gold, or whatever else is around earth, the vaccum, etc.
I think there are alot of other ‘ituitive’ analogs (i’m even working on my own variant a tiny bit and quite likely won’t fiinish it—it fairly mathematical. A deep learning algorithm or quantum computer might be able to come up with solutions in a few microseconds–and I sort of think its actually a model of those. (but a very simple ‘toy model’ the way a celular auomata is for many things.) .
. ———————-
I’ve really only skimmed a few papers by Bostrom—-not to my taste, and dealing with philosophical puzzles or ‘x-risks’ which are sort of beyond my powers of thought. (I think an old greek fable –pandora’s box—seemed to have same sort of idea. Bostrom is part iof a fairly large community called ‘effective altruism’ (associated with P Singer, and who apparently raise millions of $/yr for chairty apparently from some billionaire types as well as smaller contributions—many have math/physics backgrounds as does Bostrom.
The only paper by Bostrom that i did sort of like though i just skimmed had the ‘sleeping beauty ‘ paradox (which apparently is well known). And he apparently used hyperreal numbers to discuss or solve this (my knowledge of those is minimal, some sort of variant of infinitesimals or transfinite numbers). (That suggested to me maybe he did know math, because all the other stuff i had seen was just words. I do like quite a few ‘logical paradoxes’ of this type (eg Bertrand rssel’s–‘i am a liar’; the wine/water paradox, the order from randomness , Tarski’s , , etc. ) because they do lead to math, but usually not really applied math.
I view these as ‘innocent’ and maybe intellectually healthy excercizes like kids’ sports. Sometimes i do question given all the problems in the world whether people might put a bit more of their intellectual efforts towards solving those.
Also, i’m not convinced effective altruism (EA) , while it does some or alot, is actually ‘effective’ or optimal. Sometimes it looks like ‘stealing from peter to give charity to paul’.
I’d rather teach someone to catch a fish rather than give them a stolen one–i’m just not sure where all their millions$ come from.
———
Its quite possible i do not understand the paperchip problem, SD, or EA much if at all. I prefer my own dialect.
. ,
LikeLike
“But before we leave Mr. Clippy behind, and the larger issue of coding value sets and behaviors, let’s just take a minute and back up and consider who wrote about Paperclip Maximizer in the first place? The fundamental thesis of Mr. Clippy is that, given an objective function and NO deep understanding of value sets and how they work, this thing is gonna make paperclips and run away and kill everyone. Because it’s SO SMART.
Yet any performance grounding from around the world tells us basically all manufacturing items rely on complicated supply chains for efficiency. These supply chains have negotiated contracts and commitments to specialization for all supplies, from zinc-covered wire, to bending machines and such. Where we’ve REALLY been had is by Mr. Clippy’s creator, who obviously is an Authoritarian, and believes that even with a single objective metric, # of paperclips, that the best way to do it is to be an obsessive psychopath.”
The thing is, while the AI paperclip maximiser is a fantasy, this sort of psychopathy is far from hypothetical.
We already have paperclip maximisers in the real world: They’re called for-profit corporations and the thing they maximise is shareholder value.
As far as I can tell, the only people who benefit from them are wealthy shareholders and people who get paid in stock options, who make out like bandits. Everyone else? Their livelihoods regularly get turned into paperclips in stock market crashes, predatory business dealings, and corporate looting sprees.
People and even corporations were conducting actual business for centuries before the Shareholder Value Theory was even developed.
LikeLike
Not disagreeing with you, Matt — but this blog is about the knowledge structures that undergird all behavior. That kind of thinking is extremely complex — and far beyond the range of what AI can do now. Recommend reading this if you’re interested. https://empathy.guru/2019/04/06/what-is-structural-memetics-and-why-does-it-matter/
LikeLike